

2023: Year in Review
The past year has seen the Lab holding true to our mission of pursuing a deeper understanding of the digital economy and its impact on the future of work and society. From groundbreaking research to new collaborations to far-reaching events, here are just a few of our accomplishments in 2023.
Follow us on X and LinkedIn to keep up with the Lab and our work. While you’re at it, sign up for email updates to receive The DigDig newsletter and news about future events.
Research

Can generative AI boost productivity in the workplace? Lab researchers Erik Brynjolfsson, Danielle Li, and Lindsey Raymond tested AI software with more than 5,000 agents at an unnamed Fortune 500 company to find out. The surprising result: The company posted a 14% increase in the number of customer service chats an agent successfully responded to per hour. Another surprising finding: The boost in productivity was seen in the lowest-skilled customer service agents, while their higher-skilled counterparts experienced only a slight increase.
Related
Generative AI at Work
Arxiv
First study to look at AI in the workplace finds it boosts productivity
Axios
How to capitalize on generative AI
Harvard Business Review
Will generative AI make you more productive at work? Yes, but only if you’re not already great at your job
Stanford HAI
How generative AI is placing CFOs at the forefront of company strategy
Fortune
Brainstorm AI 2023: Economic Impacts of AI and ML on the Workforce
Fortune
Collaborations

Project Liberty brings technologists, academics, policymakers, and citizens together to improve technology, including a more open internet infrastructure. Earlier this year, the Lab, along with Stanford University, joined Project Liberty in its effort to produce a more responsible approach to digital technology. “Stanford will add an important anchor for us in Silicon Valley,” said founder Frank McCourt. Jr. “With their openness to collaboration, focus on solutions, and shared sense of urgency, Stanford faculty will help propel our work.”
Related
Project Liberty expands global alliance to strengthen democracy and responsible technology
Stanford joins international initiative to strengthen democracy and foster responsible technology
Knowledge sharing

Our 2023 Seminar Series covered a wide range of pressing topics—including productivity during the pandemic, consumer demand to support black-owned businesses, and data deserts and inequality. Catch up on all of our seminars (or watch them again) from the past year.
Related
Seminar Series 2023: Year in Review
Collaboration

The Lab began working with the ADP Research Institute in 2022 to produce the new and improved ADP National Employment Report, which measures the changes in private employment based on payroll data from more than 25 million employees. Today, that collaboration is going strong.
Events

The way we currently measure the economy is outdated—and that divide will only grow in the emerging AI-powered economy characterized by goods and services that have zero price. So how can we understand, let alone manage, what we do not accurately gauge? The New Measures of the Economy Workshop convened researchers and experts to explore new and better methods of measurement.
Related
Crafting a New Measure of Economic Well-Being
Stanford Digital Economy Lab
Research

In the working paper, “AI Adoption in America: Who What, and Where,” a team of researchers examined how 850,000 firms in the United States used five AI-powered technologies—autonomous vehicles, machine learning, machine vision, natural language processing, and voice recognition. Their findings? Fewer than 6% of firms used any of the five AI-related technologies.
Related
AI Adoption in America: Who, What, and Where
NBER
‘AI divide’ across the US leaves economists concerned
The Register
Education

In “The AI Awakening: Implications for the Economy and Society,” a Stanford course led by Lab Director Erik Brynjolfsson, students discussed and debated the ways AI will impact the future. Guest speakers included Mira Murati, Jack Clark, Laura D’Andrea Tyson, Alexandr Wang, Condoleezza Rice, Bindu Reddy, Eric Schmidt, Mustafa Suleyman, and Jeff Dean, A 2024 course is planned.
Related
The AI Awakening: Implications for the Economy and Society
Stanford Digital Economy Lab
Research

Who knew that Iowa, Michigan, Kansas, Wisconsin, and Minnesota led the nation with the highest concentration of robots in manufacturing? In the working paper titled “The Characteristics and Geographic Distribution of Robot Hubs In US Manufacturing Establishments,” Erik Brynjolfsson, J. Frank Li, and other researchers used data from the US Census Bureau’s Annual Survey of Manufacturers to examine which manufacturers use robotics, where the robots are, and how establishments are using them.
Related
The Characteristics and Geographic Distribution of Robot Hubs in U.S. Manufacturing Establishments
NBER
What ‘robot hubs’ mean for the future of US manufacturing
Stanford Digital Economy Lab
But wait, there’s more
Check out more Lab-related news and press from 2023:
What to expect in AI in 2024
Stanford HAI
Your company will need remote work as extreme weather gets worse
Harvard Business Review
The investigators of human creativity
Stanford Digital Economy Lab
Podcast: Erik Brynjolfsson on the future of generative AI
2-2-2
An approach to boosting US labor productivity
McKinsey & Company
Machines of mind: The case for an AI-powered productivity boom
Brookings

Insights
A team of researchers set out to examine how AI is disrupting the creative industry
Generative artificial intelligence tools like ChatGPT and Stable Diffusion have soared in popularity over the past several months—and so have the challenges surrounding them, including issues of authorship and credit, concerns about misinformation and the role AI could have in the media ecosystem, and ultimately the impact the technology will have on skills and jobs.
Because no matter how magical, mysterious, or automatic generative AI may seem, the content didn’t come from nowhere, and it didn’t come from the AI itself. Text-based tools are trained on the writing of human authors while image-generation software sources photos, paintings, and other illustrations made by people. At the same time, humans are ultimately responsible for how these AI tools are used and to what ends they’re applied.
In other words, the science of generative AI is similar to the science of human creativity. Now there’s a team of interdisciplinary researchers working to study how the two sciences interact. The collaboration recently spawned a new paper published in Science titled “Art and the Science of Generative AI.” The researchers, who dub themselves “The Investigators of Human Creativity,” have also produced an extended whitepaper and website (that shares the same title as the Science paper) devoted to explorations of the relationship between art and AI.
“With such a big and complex topic with so many promises and perils, like AI has, everyone has their own perspective that’s founded in their own discipline—but how can we build bridges and try to understand this together?” said Ziv Epstein, the lead author of the papers and a postdoctoral scholar at the Stanford Digital Economy Lab. “In presenting a snapshot of where we are right now, we want to toe the line between optimism and pessimism, and we want to build coalitions of people who are thinking about this so that we can pool our resources and create the space for really valuable conversations.”

Stanford Visiting Scholar
Director, MIT Human Dynamics Laboratory, MIT Media Lab Entrepreneurship Program
The project spans several disciplines and features fourteen experts, including legal scholars, computer scientists, designers, and other leaders studying how AI is impacting their various fields. Epstein is one of several Stanford Digital Economy Lab researchers involved in the project.
Morgan Frank, a Stanford Digital Fellow, led the section on the labor economics of the creative industry and the impact new AI tools will have on the field. “Our main goal was to touch on these different economic, cultural, and legal aspects of generative AI, and highlight where we think we’re going,” Frank said. “We were thinking about policymakers, the media, and the public, and we were trying to highlight what is known, and what is still yet to be known.”
The idea for the initiative arose last year at the International Conference on Computational Creativity in Bolzano, Italy. Aaron Hertzmann, who ultimately became one of the project’s contributors, spoke about the challenge of anthropomorphizing AI, making the case that the AI tools themselves produce no art—they can only put out reinterpretations of the training data that were inputted by humans. In conversations after that presentation, Epstein and others discussed how Hertzmann’s concern about misinterpretation and agency spoke to a larger issue: since the field of generative AI was developing so fast, how could experts and the public alike wrap their heads around what’s happening? These tools have enormous potential, but what are the immediate questions about how they are being created and deployed?
In the months that followed, those conversations coalesced along a few main themes: aesthetics and culture, legality and copyright, labor economics, and the media ecosystem and misinformation. The Art and the Science of Generative AI project presents a survey of those key themes, allowing for an introduction to these complex issues in hopes of creating a shared understanding going forward. Since the AI landscape touches so many industries and areas of expertise, it requires a common language to enable computer scientists to talk to artists, and for labor economists to talk to copyright lawyers. That’s what these papers seek to provide.
“This whole project was so satisfying to me because there was a consensus and a synergy to the way all of these experts were approaching the subject,” said Sandy Pentland, a visiting scholar at Stanford and one of the project’s contributors. “If you can get labor economists, AI experts, and artists to all look at a complex issue like AI in the same way, you’re going to have a pretty good picture of what is possible to know at this point.”
This collaborative approach provides more than a shared understanding of where the world of generative AI sits currently—it also creates clarity in thinking about what to study in the future. For each of the four key themes—culture, misinformation, law, and the job market—the Art and the Science of Generative AI project offers a snapshot of current concerns and trends, as well as a list of potential questions for researchers to pursue.
Theme #1: Aesthetics and Culture
Thinking about the visual quality of AI art, one possibility is that AI outputs would be trained on other AI outputs, which could create a cycle where the same style of content is produced again and again.
Recommendation algorithms, such as those that select what you see on social media feeds, add more nuance to that concern. If online creators are generating the same type of information or imagery to please an internet algorithm, it’s also likely to give us the same output repeatedly.
More worryingly, if an increasing amount of content is drawn from biased AI training data, then the technology may capture, reflect, and even amplify cultural norms and biases, potentially reducing diversity in art and design. On the other hand, using an AI tool presents a lower barrier to entry than creating similar images manually, and this may increase diversity by allowing more people to participate in creative processes. A diverse set of outputs from AI tools could also keep the art from becoming boring and potentially do a better job of reflecting human diversity.
These and other concerns suggest that future research is needed to measure diversity in AI output in order to curb homogeneity.
Theme #2: Media and Misinformation
The issue of recommendation also impacts the relationship between generative AI and the broader media landscape, including misinformation. Generative tools use far less resources than conventional media and lack many of the guardrails that consumers are used to. And production time and costs decrease, concerns about AI-generated misinformation, synthetic media, fraud, and nonconsensual imagery have risen. Deepfakes—videos edited using falsified images—are a prime example of this phenomenon.
Many relevant research questions naturally follow: How should platforms intervene to stop the spread of misinformation? How can the provenance of a piece of content be traced to ensure its reliability? And as the quality of AI-generated imagery improves, what can be done to detect that content in the first place so that audiences can understand the kind of media they’re consuming?
Theme #3: Legality and Copyright
The use of training data poses perhaps the most prominent legal issue of generative AI and art since existing copyright laws are insufficient when dealing with AI-generated content. For example, there is no legislation currently on the books that outlines compensation for the training data that AI tools consume. More research and legislation will need to establish whether AI copies what it’s taught or creates something new. These guidelines would also determine how to protect an artist’s style, keep their work protected, and compensate them appropriately.
The researchers also present a possible alternative: artists could opt-out of having their work used as training data for AI.
“The streaming era has also changed the entire music industry, and that’s what we’re worried about with AI,” Pentland said. “You get a few megastars and then lots of people making pennies. So that’s a good thing for some people, especially the streaming companies, but it’s unequal in a way that is not very positive. That’s what this article was about—there’s a lot that we’re excited about, but there are also threats. We want to be clear about what’s good and what’s bad.”
Theme #4: The Future of Work
Finally, and perhaps most practically, generative AI is set to transform work and employment, especially in creative roles. For a while now, economists have assumed that automation would not affect creative work the same way it has disrupted fields like manufacturing.
But generative AI has upended this assumption. When it comes to creative production, AI is remarkably efficient, which may lead to the same output with fewer workers. This could threaten certain creative occupations, such as writers, composers, and graphic designers—or at the very least, restructure how that work is done.
“We know that technology rarely automates whole occupations, and it’s much more common that technology automates specific tasks within a job,” Frank said. “People might be tempted to look at tools like MidJourney and assume that automation will make graphic designers a thing of the past, and I don’t think that’s likely true. Workers usually have to perform many tasks within their job, and it’s very rare to see technology replace all of them at once.”
‘The real work begins’
The four themes addressed by the project are astoundingly complex, especially given how fast generative AI tools are being developed and released—and the authors know their work can’t answer all the questions that AI raises. However, by providing a common language and a shared understanding of the current moment, Art and the Science of Generative AI can lead the way for those questions to be answered.
“This is very much the first step,” Epstein said. “There’s nothing empiric here, there’s no engineering, we’re just trying to build a common foundation for future science and research to sit on top of. And with this paper out there, now the real work begins.”
Insights
Invented a century ago, GDP was never meant to fill as many roles as it does today. A new measure of well-being, GDP-B, promises a much clearer picture of where value emerges in our changing economy.
There are several ways we can describe the value of Google Search: by the number of daily queries it fields, the vast quantity of content it contains, the myriad ways it makes life easier. Alternatively, its value is reflected in the fact that, according to a new study, most people would forgo meeting their friends in person for a month before they would give up the service.
And it costs nothing to use.
“There are lots of amazing goods with zero price these days: apps on our phones, Wikipedia, ChatGPT,” says Erik Brynjolfsson, a professor of economics at Stanford and director of the Stanford Digital Economy Lab, a center within the Stanford Institute for Human-Centered AI (HAI). And yet all of this free stuff doesn’t register in the pulse of our economy; it’s not captured by GDP. “So we’re consuming a lot of free digital things and not doing a good job measuring it.”
A new project spearheaded by Brynjolfsson and Carnegie Mellon assistant professor Avinash Collis is crafting a tool for measuring the size and value of our increasingly digital economy. Called GDP-B — the “B” stands for “benefit” — the basic hope is to understand how much value something like Google creates. Early estimates from the work suggest that trillions of dollars of value from digital goods are currently missing in discussions of the U.S. economy, to say nothing of economies around the world.
Measuring well-being, not just production
Nobel-winning economist Paul Samuelson called GDP “among the great inventions of the twentieth century.” It offers a pithy measure of an economy’s production. But it has limits. As noted above, it overlooks the economic value of most free digital goods. It also conflates the production of beneficial goods, like new wind turbines and schools, with the production that’s connected to houses destroyed by wildfire or people sentenced to prison.
“GDP was never meant to measure well-being,” says Collis. “And yet, because we lack other numbers, economists, policymakers — almost everyone — have defaulted to GDP as a proxy for our general welfare.”
GDP-B is designed to address these shortcomings. A new paper by Brynjolfsson, Collis, Stanford postdoctoral scholar Jae Joon Lee, and several collaborators from Meta offers a proof-of-concept by outlining how GDP-B can be measured and interpreted.
The researchers ran an online survey of nearly 40,000 people across 13 countries. Participants were first asked to rank a set of online goods from those they value most to those they value least. The full set of goods included Facebook, Twitter, Instagram, WhatsApp, Snapchat, TikTok, Google Search, Google Maps, YouTube, and Amazon Shopping. This provided information on the comparative value of each.
They next asked participants if they would be willing to stop using Facebook for a month in exchange for three randomly chosen dollar amounts between $5 and $100. “By seeing how many people accept the offer at each price point, we get a rough sense of its value for a representative group of people,” Brynjolfsson says. “If someone won’t give it up for five dollars but will for ten, then we know that the value of that good — its benefit to the consumer — is somewhere between those two.”
Using Facebook as a benchmark, the researchers were able to extrapolate the relative value of the other nine goods, captured in the first phase of the survey.
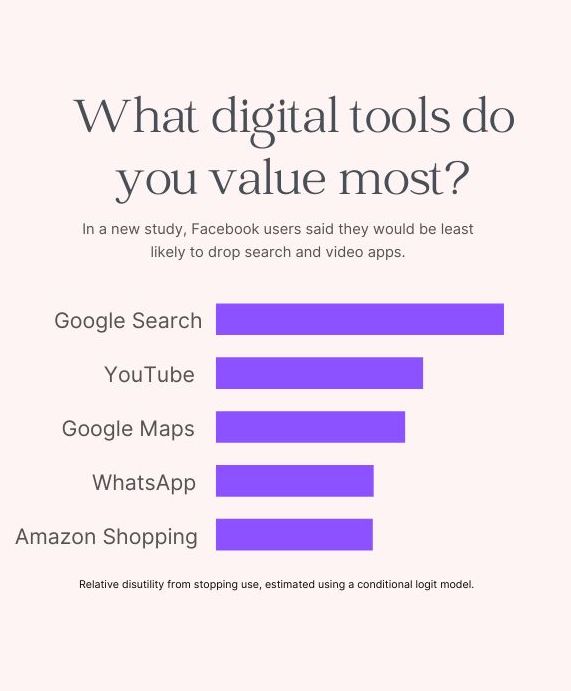
Uncovering trillions in missing value
Most fundamentally, GDP-B reveals that these 10 goods alone generate more than $2.5 trillion in annual consumer welfare across the 13 countries. This is roughly equivalent to 6 percent of their combined GDP.
Of particular interest, says Collis, was how much of this value flows to consumers. In the case of, say, breakfast cereal, a person may pay $4 for a box but be willing to pay $8; the company gets half the value and the consumer the other half. When it comes to most digital goods, this ratio tips much more favorably toward the consumer.
“Google Search may make 10 or 20 dollars a year from me, but I would say I get thousands of dollars of value from the product,” Collis says. “I can’t imagine living without it.”
“We need a metrics revolution.”
A clearer articulation of an economy’s topography is one of GDP-B’s great prospects. “In the U.S., Congress and policymakers have to make decisions about how to allocate budget dollars, how to spread R&D money or offer grants, and these decisions are often rooted in ideas about how the economy creates value,” Brynjolfsson says. “If we have the wrong measures, then we come to the wrong conclusions.”
Over the next few years, the researchers hope to expand the number of goods they’re looking at — digital and non-digital — from 10 to several thousand. This effort, Brynjolfsson suggests, could create a representative sample of the U.S. economy, giving a far more granular view into how much value different sectors create, and in what way.
GDP-B also has the potential to measure two types of good that elude the reach of traditional GDP. First, non-market items, like clean water, education, or infrastructure. “Having a nice park in a big city creates a lot of value,” Collis says. “But how much?” With the GDP-B survey methodology, governments could start attaching better numbers to historically vague domains.
Second, GDP-B can be used to define the negative value of something, like air pollution: How much would people pay to not have polluted air?
“There is a massive need for better data about how the economy is changing, how people are faring in it, and what kind of policy decisions will lead to better outcomes for more people,” says Christie Ko, executive director of the Stanford Digital Economy Lab. “The tools we have now give us poorer and poorer insight as time goes on. We need a metrics revolution to actually understand where and how progress is taking shape and how to wield this for the benefit of all.”